Offline LLM Diagnostics for Industrial Sensors
📺 Watch the System Demo featuring Quantized Inference on CPU and Real-Time Hardware Telemetry.
- The Problem: Field technicians and remote weather stations (e.g., in the Arctic or offshore) often lack stable internet connection, making Cloud-based AI diagnostics impossible.
- The Trap: Standard Large Language Models (LLMs) like GPT-4 are too heavy to run on field laptops and require constant connectivity, leading to latency and privacy risks for proprietary sensor logs.
- The Solution: NanoSentri. A Hybrid "Cloud-to-Edge" MLOps pipeline. We fine-tune a Small Language Model (SLM) on the Cloud, strictly quantize it, and deploy it as a self-contained, offline microservice capable of running on standard CPUs.
Since the quantized model (4.8GB) exceeds GitHub's file size limits, you must regenerate it using our pipeline.
We utilize Cloud GPUs for the heavy lifting to avoid local hardware strain.
- Open
notebooks/colab_runner.ipynbin Google Colab (Free Tier T4 GPU is sufficient). - Upload the synthetic dataset:
data/processed/vaisala_synthetic_train.jsonl. - Execute Phase 2 (Train): This runs
src/train_colab.pyto fine-tune Phi-3-mini using QLoRA. - Execute Phase 3 (Merge): This runs
src/merge.pyto fuse the LoRA adapters into the base model. - Download Artifact: Download the
phi3_merged_model.zip(~7GB) to your local machine.
We perform the final ONNX conversion locally to handle the large export graph without Colab RAM timeouts.
- Unzip the merged model into
backend/phi3_merged/. - Install export dependencies:
pip install -r backend/requirements_export.txt. - Run the ONNX Export & Quantization:
# Export to ONNX optimum-cli export onnx --model backend/phi3_merged/ --task text-generation backend/onnx_raw/ # Quantize to INT4 (CPU Optimized) python backend/src/quantize.py
- Final Result: You now have the
backend/phi3_export/phi3_int4_finalfolder ready for Docker.
- Engine: PyTorch + Hugging Face Transformers
- Technique: QLoRA (Quantized Low-Rank Adaptation) on NVIDIA T4 GPU.
- Model: Microsoft Phi-3-mini (3.8B) — Chosen for its high reasoning capability at a small footprint.
- Artifacts: LoRA Adapters -> Merged -> Exported to ONNX INT4.
- Runtime: ONNX Runtime (CPU Execution Provider).
- API: Python 3.11 + FastAPI.
- Optimization: Dynamic Quantization (INT4) to fit within <5GB RAM.
- Telemetry: Real-time benchmarking (Tokens/sec, RAM usage).
- Framework: React 18 + TypeScript + Vite.
- Styling: Tailwind CSS.
- UX: Real-time "Processing" states and Hardware Stats dashboard.
| Decision | Alternative Considered | Rationale |
|---|---|---|
| Model: Phi-3-mini | Llama-2-7B / Mistral | Phi-3 (3.8B) outperforms Llama-2 in reasoning benchmarks while being 50% smaller, making it viable for edge devices. |
| Runtime: ONNX | PyTorch Native | PyTorch is heavy and slow on consumer CPUs. ONNX Runtime provides hardware acceleration (AVX2/AVX512) and portability. |
| Quantization: INT4 | FP16 / FP32 | FP16 requires ~8GB+ VRAM. INT4 shrinks the model to ~4.8GB, allowing it to run on standard 8GB RAM laptops alongside other apps. |
Hardware: Standard Intel/Apple Silicon CPU (No GPU required at inference).
- Model Size: 3.8 Billion Parameters (Compressed to INT4)
- RAM Footprint: ~4.9 GB (vs. 16GB+ for uncompressed models)
- Inference Speed: ~2.1 Tokens/sec (Human reading speed)
- Cost per Diagnosis: $0.00 (Zero Inference Cost / No Cloud API fees)
The "Offline-First" Guarantee: NanoSentri ensures data sovereignty for industrial clients.
- Air-Gapped Operation: The Docker container requires zero internet access after the build.
- Data Sovereignty: Proprietary sensor logs (voltage, error codes, protocols) never leave the local machine.
- Deterministic Latency: No API timeouts or queueing; performance depends solely on local hardware.
- Docker & Docker Compose
- 10GB Free Disk Space (for Model Artifacts)
git clone https://github.com/Nibir1/NanoSentri.git
cd NanoSentri
# Ensure the model artifacts are present in backend/phi3_export/
make build
# Frontend live at http://localhost:5173
# Backend API live at http://localhost:8000/docs
make test
To verify the system's "Edge Capabilities," run the following test cases in the UI to see how the SLM handles specific Vaisala fault patterns.
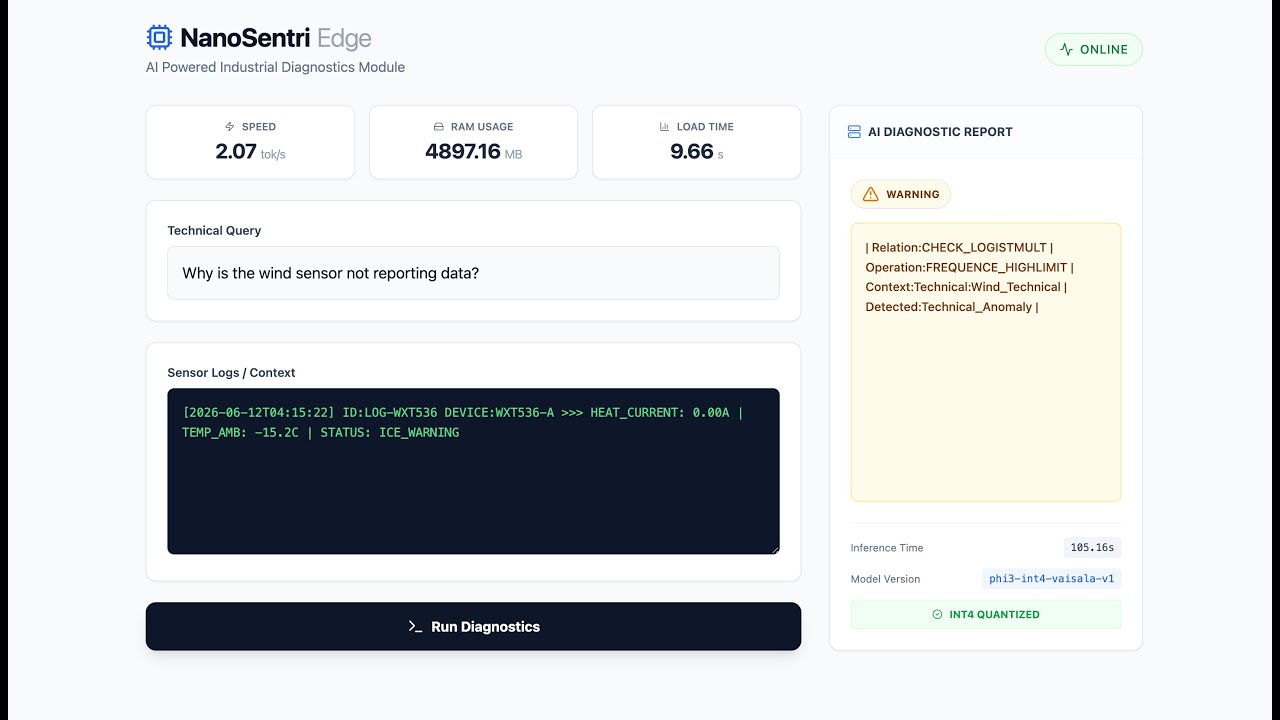
Input:
Query: "Why is the wind sensor not reporting data?" Context: "[2026-06-12] ID:WXT536 >>> HEAT_CURRENT: 0.00A | TEMP_AMB: -15.2C | STATUS: ICE_WARNING"
- Why this matters: A generic chatbot might just say "It's cold." NanoSentri detects the anomaly: The temperature is freezing (-15C), but the Heater Current is 0.00A, indicating a specific hardware failure in the heating element.
- Success Indicator: The AI identifies the Heating Element Failure and recommends checking the 24V supply lines.
Input:
Query: "Diagnose the intermittent resets." Context: "V_IN: 8.4V [LOW] | REF_CHK: FAIL | EVENT: SYSTEM_RESET"
- Why this matters: This tests the model's understanding of operating thresholds.
- Success Indicator: The system flags the 8.4V Input as below the standard operating threshold (10V-30V) and identifies it as the root cause of the Reference Check failure.
We utilize a Makefile to standardize the development lifecycle across the engineering team.
| Command | Description |
|---|---|
make build |
Forces rebuild to ensure dependencies are fresh |
make up |
Starts the full Dockerized stack (Backend + Frontend) |
make down |
Stops containers and cleans up networks |
make test |
Runs the 100% Coverage suite (Pytest + Vitest) inside containers |
make clean |
Removes cache artifacts (pycache, etc.) |
A clean "Monorepo" architecture designed for easy auditing.
NanoSentri/
├── backend/
│ ├── src/
│ │ ├── generator.py # Synthetic Data Factory
│ │ ├── train_colab.py # Cloud Training Script (QLoRA)
│ │ ├── export_model.py # ONNX Export Logic
│ │ ├── inference_edge.py # FastAPI Inference Engine
│ │ └── utils.py # Logging Utilities
│ ├── tests/ # Pytest Suite (100% Coverage)
│ ├── phi3_export/ # Quantized Model Artifacts (INT4)
│ └── Dockerfile # Python 3.11 Inference Container
├── frontend/
│ ├── src/
│ │ ├── components/ # Dashboard UI Components
│ │ ├── __tests__/ # Vitest Suite (UI Logic)
│ │ └── App.tsx # Main Dashboard Logic
│ └── Dockerfile # Multi-stage Node -> Nginx Build
├── notebooks/ # Jupyter Notebooks for Cloud Training
├── docker-compose.yml # Orchestration (Port 8000 <-> 5173)
└── Makefile # Automation Scripts
Architected by Nahasat Nibir